Bienvenue sur mon site #vtecl !
Ci-après, vous trouverez le compte-rendu de mon travail réalisé dans le cadre du module de veille technologique à l'École Centrale de Lyon. Si vous êtes sensible à la notion de « e-réputation » et que vous vous posez des questions quant à son évolution, vous êtes au bon endroit. L'objectif n'est pas ici d'être exhaustif, surtout avec un sujet aussi large. L'idée est plutôt de cerner l'ensemble pour bien comprendre ce qui est en train de se passer.
Il me reste alors à vous souhaiter une bonne lecture...

Introduction
Nous sommes en 2014. Internet gagne progressivement du terrain et s'invite un peu partout dans l'espace sociétal. Rélégué jadis au rang de simple outil de communication scientifique et militaire, Internet a aujourd'hui franchi bien des frontières, au point d'être devenu l'un des piliers de la vie contemporaine. Aussi n'est-il pas nécessaire d'être un expert pour se rendre compte de l'envergure des mutations opérées depuis l'ARPANET (1969) jusqu'à la rédaction de ces lignes.
Alors que nous convergeons vers un modèle de connectivité ubiquitaire, il devient crucial de se poser des questions sur le devenir de notre e-réputation. Et au-delà de toutes les définitions théoriques que nous pourrions donner dans ce rapport, n'importe quelle personne morale ou physique un tant soit peu concernée par les problématiques de sécurité informatique aura vite compris l'enjeu d'un tel sujet. Car, certes, l'informatique connectée nous apporte un confort qu'il est maintenant difficile de nier. Cependant, comme souvent, il convient de ne pas oublier le revers de la médaille. Nous y reviendrons.
Par ailleurs, en pratique, cette veille prend comme point de départ le « Web 3.0 ». Il est néanmoins préférable de présenter les choses dans leur contexte, donc nous aborderons aussi la question du « Web 1.0 » et du « Web 2.0 », aussi bien à l'échelle individuelle qu'organisationnelle.
e-Réputation ?
La définition de la « e-réputation » est assez intuitive. De manière très concrète, il s'agit de l'image que chacun de nous renvoie dans l'espace numérique. Quand on parle de « e-réputation », il y a donc fondamentalement la notion de perception qui intervient. En tant qu'individu, je peux choisir ce que je veux montrer ou ne pas montrer aux internautes. Ces derniers sont ensuite libres d'interpréter, en fonction de leur tempérament, les informations auxquelles ils sont confrontés. Notre e-réputation n'est donc pas nécessairement une transposition de notre réputation « réelle » (celle du quotidien) dans le virtuel. Une personne ayant une mauvaise réputation dans le monde physique peut tout à fait avoir une bonne réputation dans le monde numérique, et vice versa. En effet, bien qu'appartenant au même univers, la réalité physique et la réalité virtuelle (pas au sens graphique de l'expression) sont régies par leurs propres règles. Rien n'empêche donc un bon père de famille de devenir le troll de l'année sur les forums, de la même manière que rien n'empêche un pédophile de se faire passer pour une petite fille sur un tchat électronique.
En tout état de cause, nous devons différencier ce que les anglophones appellent le « personal branding » et le « corporate branding » ; à savoir la marque personnelle et la marque d'entreprise. Les deux notions n'ont évidemment pas les mêmes enjeux, mais nous verrons tout de même que la question de la e-réputation se pose sérieusement, que l'on soit un citoyen lambda ou une organisation.
Web x.0 ?
Depuis quelques années, on entend beaucoup parler du « Web 2.0 ». Tous les médias s'y intéressent. Mais sait-on réellement de quoi il s'agit ?
Autant le dire d'emblée, l'appellation « Web 2.0 » n'a aucune légitimité scientifique ou technique, tout comme l'ensemble des versions du Web qu'on a pu identifier par extrapolation. Le Web n'est pas un logiciel : c'est un système réparti. Donc il convient de le traiter en conséquence ! Mais même si le Web n'a pas de versions à proprement parler, son évolution repose sur des tendances aisément observables empiriquement, et c'est là que cette classification marketing va nous aider. Naturellement, ces tendances ne concernent pas forcément le Web au sens strict, mais plutôt l'écosystème dans lequel il s'inscrit. À ce titre, le lecteur ne sera pas surpris par la largeur du champ d'analyse...
Quoi qu'il en soit, par « Web x.0 », on entendra deux choses. Le premier sens donné à cette expression renverra à une « version » indéterminée du Web (1.0, 2.0, 3.0, etc.). Le second sens est, quant à lui, explicité dans la chronologie ci-dessous :
Web 1.0
Le « Web 1.0 » correspond à la toute première « version » du Web. Il correspond donc au Web qui est arrivé au début des années 1990 grâce à l'esprit créatif de Tim Berners-Lee, alors chercheur au CERN. À cette époque, le Web était plutôt statique et unilatéral dans la mesure où l'on y échangeait surtout des pages HTML via HTTP ; les sites web étant, par essence, des sites vitrines qui ne laissaient que très peu de possibilités d'interaction (pour l'anecdote, il a fallu attendre 1996 pour voir l'arrivée de JavaScript dans le navigateur Netscape...). C'est d'ailleurs à cette époque que les annuaires de liens – comme celui de Yahoo! – étaient largement utilisés à des fins de recherche. Aujourd'hui, nous avons complètement abandonné cette méthodologie au profit des moteurs de recherche, ce qui dénote un changement radical de paradigme entre-temps.
Web 2.0
Le « Web 2.0 » a émergé au début des années 2000, et l'on doit principalement l'usage commun de cette expression à Dale Dougherty ainsi qu'à Tim O'Reilly. Contrairement au « Web 1.0 », le « Web 2.0 » se veut participatif, social, et communautaire. L'idée est de rapprocher le citoyen lambda de l'informatique, et en particulier de l'Internet qui est devenu un véritable espace d'expression pour tout un chacun. On connaît bien sûr le « Web 2.0 » au travers des géants du social comme Facebook, Twitter, ou YouTube, mais le paysage 2.0 est certainement plus riche que ce qu'on imagine de prime abord...
Non, le « Web 2.0 » n'est pas qu'une vulgaire liste de réseaux sociaux. On y trouve aussi les blogs, les forums, les wikis, les plateformes de partage de contenu audiovisuel, les journaux participatifs, le shopping communautaire, les avis/recommandations, et bien d'autres outils de travail collaboratif...
Finalement, le « Web 2.0 » marque la prise de pouvoir de l'internaute. Il n'est plus passif, comme à l'heure du « Web 1.0 », mais bel et bien actif ! Ce qui fait la force de cette « version » du Web, c'est donc ce que l'on appelle l'UGC (« User Generated Content »), ou plus généralement le « crowdsourcing » (approvisionnement par la foule). L'internaute peut ici s'exprimer librement sur des sujets qui lui tiennent à cœur.
Web 3.0
Les contours du « Web 3.0 » sont actuellement sujets à controverse. Pour certains, le « Web 3.0 » n'est ni plus ni moins que le Web sémantique. Pour d'autres, le « Web 3.0 » correspond au Web des objets. Et puis certains vont même jusqu'à penser le « Web 3.0 » comme une sorte de « Web 2.0 » exacerbé où l'activisme façon Anonymous prendra une importance considérable.
En ce qui nous concerne, nous adopterons une vision un peu plus large afin de cerner de manière plus ou moins exhaustive le cœur et l'environnement de ce que pourrait être le « Web 3.0 ». Nous partirons donc du principe que cette « version » du Web en devenir englobe des thématiques fondamentales comme le Web sémantique, l'Internet des Objets (IdO), le « cloud computing », la réalité augmentée, et la mobilité.
Web x.0
Le « Web x.0 », en tant que « version » postérieure au « Web 3.0 », en est encore au stade de la science-fiction. Mais au vu des constats que l'on peut déjà dresser vis-à-vis de l'évolution fulgurante d'Internet, il va sans dire que l'on tend vers une connectivité ubiquitaire. Un penseur comme Joël de Rosnay, qui parle déjà de « Web 5.0 », en est à imaginer l'homme augmenté, un « cybionte » ultraconnecté qui ne fait qu'un avec le réseau informatique mondial. Dans le futur, il est probable que nous disposions tous d'une adresse IP pour identifier nos corps biologiques dans une sorte de matrice tirée de l'imagination des Wachowski.
e-Réputation & Web 1.0
L'intérêt principal du « Web 1.0 » en matière de e-réputation était en quelque sorte de faire acte de présence dans l'espace numérique. Il ne faut pas oublier que le Web reste avant tout un média de diffusion, et donc au début, avoir une page à son nom permettait de faire un peu de publicité. C'est toujours vrai de nos jours. En outre, comme le contenu était globalement statique et que le nombre d'internautes était relativement limité (cf. graphique ci-dessous), il n'y avait pas autant de risques de piratage qu'aujourd'hui. Selon la loi de Metcalfe, on sait effectivement que « L’utilité/La valeur d’un réseau est proportionnelle au carré du nombre de ses utilisateurs ». De fait, plus il y a d'utilisateurs du réseau, plus Internet est utile et a de la valeur, et plus cela va intéresser les contrevenants, pour diverses raisons. Par analogie, si un pirate cherche la gloire en paralysant un maximum d'ordinateurs personnels, il serait idiot de développer un malware qui s'attaque à Linux. Mais pour rester concrètement dans le sujet qui nous concerne, les pirates n'avaient pas grand-chose à gagner à l'ère du « Web 1.0 », et ils n'avaient certainement pas autant de leviers d'action qu'aujourd'hui.
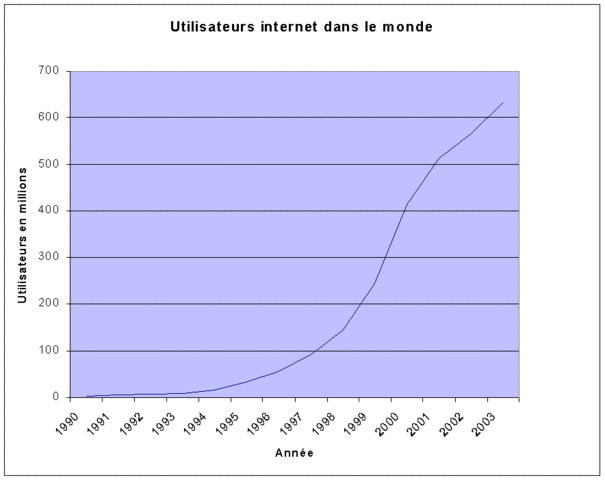
On peut donc dire que gérer sa e-réputation à l'ère du « Web 1.0 » n'était pas d'une difficulté extrême. La plupart du temps, il suffisait de maintenir un ensemble de pages statiques dans l'esprit vitrine pour être visible dans l'espace numérique. L'objectif était plus de proposer du contenu à consulter que d'interagir avec les internautes (un peu comme pour la télévision, la radio, ou le journal, dans leur conception traditionnelle). Petit point de détail néanmoins sur l'accessibilité : avant l'implémentation des feuilles de style CSS en 1996, la mise en page des sites web était souvent le fruit de bricolages en HTML (tableaux intempestifs, éléments masqués, etc.) qui rendaient les sites complètement incohérents sur le plan de la structure, et donc complètement inexploitables pour les déficients visuels. Tout cela manquait cruellement de sérieux...
e-Réputation & Web 2.0
Comme on pouvait s'y attendre, la gestion de notre e-réputation à l'ère du « Web 2.0 » n'est plus forcément une partie de plaisir. Les utilisateurs de la Toile sont bien plus nombreux qu'ils n'ont pu l'être dans les années 1990, et surtout, ils en sont devenus les acteurs. Le « Web 2.0 » étant bien plus accessible que son prédécesseur, il est devenu très facile pour n'importe qui de faire n'importe quoi n'importe où (et nous ne parlons pas seulement de l'illustre Rémi Gaillard...). Cela va de l'avis élogieux sur un produit à l'usurpation d'identité, en passant par l'épanchement de sa vie sentimentale sur un blog personnel de mauvais goût. Sur ce dernier point, et pour ceux qui ont de la mémoire, rappelez-vous du niveau intellectuel général pendant l'âge d'or des Skyblogs... La question qui se pose, c'est donc la suivante : comment gérer concrètement notre e-réputation à l'ère du « Web 2.0 » ? Dans les paragraphes suivants, nous apportons quelques éléments de réponse.
La première chose à faire pour avoir une bonne réputation, c'est d'avoir une présence pertinente sur les médias sociaux, en évitant si possible les inepties et en évitant aussi d'étaler sa vie privée sur la place publique. Pour faire un peu le tri dans ce qu'il faut ou non mettre en ligne, on peut catégoriser les informations à l'aide d'une matrice aussi simple qu'utile. Cette matrice nous vient de l'imagination de Fadhila Brahimi et prend la forme suivante :
| Privé | Public | |
|---|---|---|
| Personnel | ||
| Professionnel |
En tout cas, les entreprises le savent bien : une absence complète de l'univers « social media » est un véritable handicap, notamment dans le B2C. Pour les particuliers, entretenir une vraie présence digitale est un plus, notamment d'un point de vue professionnel. On sait effectivement que bon nombre de recruteurs résistent difficilement à la tentation de « googliser » les candidats, surtout quand ces derniers postulent dans le secteur du numérique. Mais attention ici aux options de confidentialité quand vous menez « plusieurs vies » sur Internet. Vous n'avez pas envie que vos photos de soirée sur Facebook se confondent à votre profil professionnel sur LinkedIn.
En dépit de cette réalité, certains choisissent d'aller à contre-courant en jouant la carte de l'anonymat. Mais attention à cette stratégie car, d'une part, on n'est jamais vraiment anonyme sur Internet, et d'autre part, cela laisse une porte grande ouverte pour l'usurpation d'identité. Imaginons un instant qu'une personne de votre entourage ne vous apprécie guère et décide de vous nuire d'une manière assez subtile. Si cette personne remarque que vous n'avez aucun profil à votre nom sur Internet (NameChk peut aider...), elle peut se faire un plaisir de créer des comptes factices pour les remplir avec des insanités ou les utiliser à des fins peu louables (typiquement : un compte Facebook, une adresse e-mail, etc.). Inutile de préciser alors qu'il est ensuite bien difficile de réparer les pots cassés au vu de la persistance des empreintes numériques... Vous pouvez toujours essayer d'écrire à Google pour retirer des résultats, mais c'est loin d'être gagné d'avance. Quant aux sociétés qui vous promettent d'effacer vos traces, beaucoup pratiquent l'obfuscation en noyant vos données compromettantes dans du bruit informatif. Donc les données sensibles sont toujours là, quelque part. Il y a peu de chances pour que tout disparaisse d'un coup, comme par magie.
Maintenant, parlons un peu de webmarketing ; en dehors du « community management », SMO (« Social Media Optimization »), et SMM (« Social Media Marketing ») que nous venons d'évoquer de manière implicite...
Tout d'abord, pour soigner sa e-réputation, les particuliers et les professionnels disposent d'une arme redoutable connue sous le nom de « référencement naturel » ou SEO (« Search Engine Optimization »). Imaginons que vous disposiez vous-même d'un blog sur lequel vous passez un temps non négligeable. Si ce blog est mal référencé, autrement dit s'il ne respecte pas les règles élémentaires pour jouir d'une bonne indexation et d'un positionnement correct, vous risquez fort de passer inaperçu avec vos articles. Pour donner de la visibilité à une page, un blog, un site, il convient donc de respecter les directives données par les moteurs de recherche. Bien sûr, cela ne vous dispense pas de vous positionner sur certaines requêtes grâce à une étude minutieuse des mots-clés s'inscrivant dans la « longue traîne » (cf. Chris Anderson).
En revanche, pour les entreprises, le référencement naturel est souvent une condition nécessaire mais non suffisante. Dans le cas des start-ups en particulier, il y a un vrai besoin d'être visible tout de suite, notamment par le biais de campagnes de liens sponsorisés. On a alors recours au deuxième penchant du SEM (« Search Engine Marketing ») qui n'est autre que le SEA (« Search Engine Advertising »). Le référencement naturel est en effet un travail de longue haleine, et la plupart du temps, il faut attendre des mois avant de voir arriver les premiers résultats. Or, une campagne Adwords (pour ne citer que le service de Google...) permet d'apporter un trafic de court terme qui correspond bien aux attentes des start-ups.
Parmi les autres leviers du webmarketing qui interviennent évidemment sur la notion de e-réputation, on trouve d'abord le « display ». Cette méthode de diffusion, qui renvoie aux campagnes de bannières, permet aux annonceurs de renforcer leur notoriété grâce à une présence visuelle accrue. Il en va d'ailleurs de même pour l'affiliation, quand celle-ci n'est pas en marque blanche (puisque, dans ce cas précis, la marque de l'affilieur est alors masquée par l'affilié).
Fidèle au poste, l'e-mail a aussi un rôle à jouer en e-réputation. Dans le cas des entreprises, une newsletter intelligemment envoyée saura fidéliser la clientèle en lui montrant qu'il y a un vrai suivi au-delà des achats. En revanche, un envoi intempestif d'e-mails pour des propositions commerciales aura vite fait d'agacer les gens (surtout s'il n'y a pas d'opt-in derrière), et vous finirez avec une réputation de spammeur (voire carrément de fraudeur si la LCEN n'est pas respectée). La conséquence, c'est que plus personne ne lira vos messages, en plus de donner une mauvaise image de votre marque.
Enfin, dernier levier qu'il est important d'évoquer : le « retargeting » ou reciblage publicitaire. Pour les entreprises, ce levier est intéressant car il permet d'être présent aux yeux des consommateurs qui sont potentiellement intéressés par leurs offres. Cependant, cela sous-entend qu'il y a de puissants mécanismes de tracking derrière, reposant notamment sur les fameux cookies. Il y a donc de vraies questions à se poser en matière de vie privée car il y a fort à parier que tout le monde n'ait pas envie d'être espionné en temps réel par les régies publicitaires...
Pour les curieux, mais pas seulement : il est parfois bon de faire un point sur son influence en ligne, et pour cela, certains outils nous facilitent la tâche. C'est notamment le cas de Klout ou Social Mention.
e-Réputation & Web 3.0
e-Réputation & Web sémantique
A priori neutre et purement technique, le Web sémantique est pourtant une (r)évolution majeure de la Toile qui va impacter de manière certaine notre e-réputation. Le Web sémantique n'en est encore qu'au stade de développement dans l'esprit de Tim Berners-Lee, mais on voit bien les enjeux se dessiner petit à petit.
Première piste de réflexion : le Knowledge Graph de Google, mis en place en 2012. Wikipédia le définit comme étant « une base de connaissance utilisée par Google pour compiler les résultats de son moteur de recherche avec des informations sémantiques issues par ailleurs de sources diverses. » Très concrètement, vous avez déjà dû voir le rectangle qui s'affiche en haut à droite dans les SERPs (« Search Engine Results Pages ») de Google pour certaines recherches ; par exemple : « mozart ». Ce rectangle informatif est la plupart du temps issu de Wikipédia, et l'intérêt de la manœuvre, c'est bien entendu de mettre en avant les données potentiellement intéressantes pour l'internaute. Dans le cas de la requête concernant Mozart, on constate que Google nous donne des recherches associées pertinentes. En cliquant dessus, une bande de navigation graphique apparaît, et l'on accède aux informations sur les autres compositeurs suggérés. Si le principe semble ici intéressant (et il l'est), il n'en reste pas moins à double tranchant. En effet, si vous avez une bonne réputation, celle-ci se voit valorisée dans Google. Mais même si vous avez une mauvaise réputation, celle-ci se voit également valorisée dans Google. Aussi une recherche sur Bernard Madoff donne-t-elle des résultats peu glorieux pour la personne concernée, puisqu'il apparaît en gros que l'on a affaire à un escroc. Et bien entendu, en cliquant dans les recherches associées, on a un beau trombinoscope des escrocs de la finance...
Deuxième piste de réflexion : la notion même de « Linked Data », chère au cœur de Tim Berners-Lee. On sait que le Web avance dans une direction où les données seront idéalement riches de sens et interconnectées de manière complexe grâce aux apports de la galaxie technologique qu'est XML. Or certains sites jouent déjà la carte de l'interconnexion, ce qui n'est pas forcément à voir d'un très bon œil... Prenons comme exemple le cas classique des moteurs (ou métamoteurs) de recherche de personnes tels que 123people, Yatedo, ou encore Yasni. Le principe derrière ces outils, c'est d'agréger des informations présentes sur le Web au sujet des personnes pour en faire une sorte de résumé automatique ; sans le consentement des personnes fichées, bien entendu... Si vous êtes « clean », tout va bien. Mais si vous avez la malchance d'avoir ne serait-ce qu'un contenu compromettant, il n'est pas impossible qu'il soit mis en valeur dans le résumé.
Troisième piste de réflexion : le « text mining », qui rend l'obfuscation inutile. Pour expliquer tout cela, on va commencer par l'obfuscation en se mettant dans la tête d'un référenceur (ou professionnel de SEO). Typiquement, lorsqu'un lien dans les SERPs de Google renvoie vers un résultat compromettant, le réflexe est de vouloir le cacher. D'après certaines études, dont celle de la société Synodiance, « 90 % des clics sont concentrés sur les 3 premiers liens », et on sait pertinemment que très peu de gens vont au-delà de la première page. Si un lien compromettant apparaît en tête, l'idée est alors de créer une multitude de pages (comme par exemple des profils sociaux) pour repousser ce résultat vers le bas, jusqu'à ce qu'il soit suffisamment loin pour passer inaperçu. Or, avec le text mining, les machines deviennent capables d'extraire des informations de différentes sources pour produire une synthèse cohérente qui n'est plus seulement dans la logique d'agrégation. C'est ce que propose notamment de faire SenseBot (mais l'outil ne fonctionne pas très bien). Noyer les résultats compromettants dans du bruit informatif devient donc inutile car ce qu'on essaie de cacher apparaîtra potentiellement dans la synthèse automatique.
Quatrième et dernière piste de réflexion pour le cas du Web sémantique : l'intelligence artificielle. Cette expression évoquera à certains le film A.I. de Steven Spielberg, voire I, Robot d'Alex Proyas ou encore Terminator de James Cameron ; ce qui n'est d'ailleurs pas du tout hors de propos. Si les machines deviennent capables de comprendre le sens profond des informations humaines, on peut être à la fois enthousiaste pour cette réussite scientifique et inquiet pour les implications que cela peut avoir sur la société. Dans le cas qui nous concerne, on prendra surtout l'exemple du langage naturel. De prime abord, on pourrait penser qu'il est bien difficile pour une machine de comprendre véritablement ce que nous exprimons. Pourtant on voit déjà des avancées notables dans les technologies de reconnaissance vocale et dans le monde du « search ». Certains moteurs de recherche comme Evi sont déjà capables de comprendre et de répondre à des questions en langage naturel, bien que la technologie soit encore loin d'être infaillible. Mais si un jour l'interrogation des moteurs se fait universellement en langage naturel, cela signifie que les informations seront plus faciles à trouver, et que donc il deviendra crucial de soigner sa e-réputation de A à Z. Aujourd'hui, la recherche d'informations repose largement sur des mots-clés et sur des opérateurs. Or peu de monde connaît les opérateurs de recherche, en dehors des professionnels du numérique (par opérateurs, on entend par exemple « filetype » pour chercher un format précis, « site » pour chercher sur un domaine, les guillemets pour une requête exacte, etc.). Quoi qu'il en soit, ce n'est certainement pas la complexité algorithmique qui retiendra les ingénieurs dans l'élaboration des modes de communication et d'accès à l'information de demain. Certains professionnels sont même allés jusqu'à créer un service en ligne capable de constituer votre avatar virtuel, totalement autonome, en se basant sur l'ensemble de votre activité sur Internet. Le principe est alors de vous rendre éternel, vos proches pouvant interagir avec votre avatar après votre mort (cf. Eterni.me).
e-Réputation & Internet des Objets
L'Internet et/ou le Web des objets est sans conteste l'un des sujets brûlants du moment car cette thématique déchaîne véritablement les passions sur la blogosphère. Mais pourquoi un tel engouement ? Et surtout, quel rapport avec la problématique qui nous préoccupe ?
À vrai dire, l'Internet des Objets (IdO), c'est d'abord 80 milliards de dispositifs connectés à Internet d'ici à 2020, si l'on en croit l'IDATE. Pour le moment, le « grand public » connaît surtout l'ordinateur connecté (ou PC), le téléphone connecté (ou smartphone), la tablette tactile connectée, la console de jeux connectée, la TV connectée, et plus récemment la montre connectée. Mais petit à petit, ce sont tous les objets du quotidien qui vont être « aspirés » par le réseau, devenant ainsi des terminaux communiquants via des protocoles. Avec l'Internet des Objets, nous allons assister à l'avènement du M2M et au renforcement du « Big Data » car toute activité humaine autrefois banale deviendra l'objet d'une collecte, d'un traitement, et d'une communication entre machines. Très concrètement, nous vivrons bientôt dans des « smart homes » et « smart cities » où toutes nos interactions avec l'environnement seront potentiellement analysées. Autant dire qu'il s'agirait là du coup de grâce pour notre sacro-sainte vie privée !
Cependant, il n'est pas illusoire de penser que nous tendons vers ce modèle qu'est la surveillance de masse, et il ne faut pas aller chercher bien loin pour en avoir l'intime conviction... Faisons bien sûr référence au scandale PRISM, autrement dit au programme d'espionnage global mené par la NSA, et révélé au grand jour par Edward Snowden l'année dernière. Si l'on ajoute à cela des outils comme Shodan et Thingful qui permettent d'accéder à des informations sur les objets à distance (y compris les webcams), via le réseau, il est légitime d'avoir quelques craintes pour l'avenir.
Pire encore : l'Internet des Objets constituera un immense terrain de jeu pour les informaticiens malintentionnés. La société Proofpoint, par exemple, a déjà détecté une attaque sur l'Internet des Objets, utilisant notamment un réfrigérateur en guise de relai malveillant. Mais lorsque cela devient dramatique, c'est quand ces attaques sont dirigées à l'encontre des BAN (pour « Body Area Networks »), ou autrement dit les technologies afférentes au « wearable computing ». Alors, certes, ce n'est pas bien grave si un cracker arrive à savoir combien j'ai fait de pas dans la journée en piratant mes chaussures ou mon bracelet. En revanche, le piratage d'un pacemaker est critique ! Dans le dixième épisode de la deuxième saison de la série américaine Homeland, des terroristes souhaitent assassiner le vice président en s'introduisant dans son pacemaker à distance, via une liaison sans fil. A priori, il s'agit ici de pure fiction. Et pourtant, quelqu'un l'a déjà fait dans le monde réel, loin des caméras de cinéma ou de télévision. L'Internet des Objets n'est donc pas qu'une menace pour notre vie privée : c'est une menace pour notre vie tout court, si cette évolution sociale et technologique ne s'accompagne pas de mesures fermes et d'un cadre juridique suffisamment solide.
e-Réputation & Cloud computing
Tout comme l'Internet des Objets, le « cloud computing » est incontestablement l'un des sujets chauds de ces dernières années ; d'autant plus depuis les révélations de Snowden et la prise de conscience des implications du Patriot Act (qui permet notamment aux autorités américaines d'accéder aux données stockées sur un serveur américain sans réelle restriction). Or, que ce soit pour les particuliers ou les entreprises, il n'est pas agréable de savoir que les données que l'on a transférées ailleurs sont consultées par des tiers sans notre consentement, en particulier s'il s'agit de données sensibles pouvant nuire à notre e-réputation. La grande question derrière le Cloud, c'est donc de savoir s'il est sûr et étanche.
Selon Pierre-José Billote, président d'EuroCloud France, il convient d'expliquer la transition progressive de l'informatique classique vers les nuages à l'aide de la métaphore bancaire. D'après lui, « Passer du mode informatique traditionnelle au mode Cloud, c'est passer du coffre-fort au service bancaire. » Devons-nous donc faire confiance au cloud computing ? Si l'on conserve l'analogie jusqu'au bout, le Cloud n'est pas sûr à 100 % car des gens malintentionnés peuvent très bien braquer une banque ou attaquer des convoyeurs de fonds. Mais l'informatique traditionnelle ne l'est pas non plus car personne n'est à l'abri d'un cambriolage à domicile. In fine, il semblerait donc que le niveau de risque soit le même entre l'informatique traditionnelle et le cloud computing ; avis que ne partagent pas certains personnages emblématiques tels que Steve Wozniak, co-fondateur d'Apple, ou encore Richard Stallman, père du logiciel libre. Pour eux, le Cloud représente un danger pour les utilisateurs en ce qu'il tend à les déposséder de leurs propres données, ce qui constitue une atteinte à une liberté fondamentale.
Quant aux organisations, il y a en particulier une question qui revient systématiquement, à partir du moment où la DSI a pris la décision de construire ou de migrer des services dans les nuages. Cette question a trait aux différents types de déploiement du Cloud (privé, public, hybride), qui posent inévitablement un dilemme confidentialité/coûts, et même plus largement un dilemme sécurité/coûts.
Petite anecdote pour finir, histoire de faire le lien avec la sous-partie précédente : Cisco a récemment lancé l'idée du « fog computing », une sorte de Cloud optimisé pour l'Internet des Objets. L'idée semble séduisante car l'IdO est loin du modèle traditionnel auquel nous sommes encore habitués. Espérons juste que cette initiative ne créera pas trop de brouillard sur la planète e-réputation...
e-Réputation & réalité augmentée
A priori anodine pour notre e-réputation, de la même façon que le Web sémantique, la réalité augmentée (RA) n'est pourtant pas sans conséquences. Pour bien cerner la question, il convient d'établir quatre axes de réflexion.
Le premier axe porte sur le couple RA/géolocalisation. En effet, si l'on prend par exemple un navigateur comme Wikitude, il apparaît rapidement qu'une telle application peut vite faire ou défaire une réputation numérique ; en particulier pour les enseignes de proximité. Imaginons que vous passiez devant une boulangerie-pâtisserie avec votre smartphone en mode RA. Si vous voyez que l'enseigne a un score minable et des commentaires désastreux, il y a peu de chance que vous vous y arrêtiez. À l'inverse, si votre smartphone vous dit que le pain est divin et les gâteaux succulents, vous allez peut-être sauter sur l'occasion pour y faire un tour. D'une certaine manière, c'est donc la réalité augmentée qui fait ici la pluie et le beau temps pour l'enseigne. Il est loin le temps du bouche à oreille classique...
Le deuxième axe de réflexion est un point délicat puisqu'il concerne la reconnaissance faciale. Depuis quelques mois, dans le sillage des Google Glass, on voit plusieurs sociétés qui développent des lunettes à réalité augmentée. Et si le concept est plutôt attrayant d'un point de vue technologique, il pose de vrais problèmes d'un point de vue légal et réglementaire. Aussi des personnes qui portaient ces lunettes ont-elles été arrêtées (au cinéma, en voiture, …) pour être interrogées au sujet de leur usage des Google Glass. En outre, Google a officiellement interdit les applications de reconnaissance faciale sur ses lunettes connectées, mais on sait d'ores et déjà que des développeurs tiers travaillent dessus. De telles applications arriveront donc sur le marché bien plus rapidement qu'on ne l'imagine, ce qui veut dire que n'importe qui pourra avoir sur vous des informations en temps réel en scannant discrètement votre visage. Une mauvaise e-réputation deviendrait vite handicapante dans ces conditions.
Poursuivons avec le troisième axe, au scénario quelque peu apocalyptique : et si la réalité augmentée était en train de créer une société de zombies ? Non, nous ne sommes pas dans un film de Romero, mais la question n'est peut-être pas si disproportionnée qu'on pourrait le croire... Imaginons une société dans laquelle chaque citoyen disposerait de lentilles connectées à réalité augmentée, comme c'est par exemple le cas dans le film Sight. Les interactions sociales, humaines, et physiques, seraient-elles aussi fortes que maintenant ? Ne seraient-elles pas plutôt simulées, à tel point que la vie virtuelle prendrait le pas sur la vie physique ? Le repli sur soi ne deviendrait-il pas la norme ? L'auteur de ces lignes a aujourd'hui 24 ans, et il a bien conscience que le lien social était fondamentalement différent lorsqu'il n'y avait pas Internet ni même de téléphone portable. Certaines personnes d'une autre génération considèrent volontiers que les jeunes de 2014 sont déjà devenus des zombies devant leurs « gadgets électroniques », ces derniers préférant discuter sur Facebook avec les copains plutôt que d'organiser une sortie avec eux, ou jouer à Candy Crush Saga en plein repas familial. C'est ce type de constat que dresse d'ailleurs Raffaele Simone dans son ouvrage Pris dans la Toile, en particulier lorsqu'il observe les gens dans le train. Alors si on commence à porter de l'électronique sur la tête, 24h/24, qui sait ce qui va advenir du lien social ; chose qui est assez paradoxale à l'ère de la communication sans frontières. Internet rend-il bête, comme l'exprime Nicholas Carr dans son livre du même nom ?
Quant au quatrième et dernier axe de réflexion, revenons à des choses plus prosaïques avec la promotion personnelle grâce à la réalité augmentée. En fait, la RA est un formidable moyen de se mettre en valeur, notamment d'un point de vue professionnel. Pour illustrer notre propos, nous pouvons prendre l'exempe du CV de David Wood qui repose sur le principe des marqueurs, ou encore le CV de Victor Petit basé sur un code QR. Les deux idées sont excellentes et devraient en inspirer plus d'un à l'avenir...
e-Réputation & mobilité
La mobilité est une thématique que nous avons déjà abordée implicitement en traitant le cas de l'Internet des Objets. Un smartphone, une tablette, une montre connectée, des lunettes à réalité augmentée... Tous ces objets sont mobiles dans le sens où on peut les transporter partout, ou presque. Mais il convient néanmoins d'aborder le concept de mobilité un peu à part, et c'est d'ailleurs ce qui justifie que nous lui consacrions une sous-partie dans ce rapport.
Quand on parle de mobilité, et si vous êtes marketeur, vous allez certainement penser au SoLoMo (Social, Local, Mobile). Cette tendance, largement incarnée par Foursquare, est clairement au carrefour du « Web 2.0 » et du « Web 3.0 ». D'une certaine manière, comme on a pu le voir avec l'Internet des Objets, la mobilité est une révolution qui n'en est qu'à ses premiers balbutiements. L'Internet mobile est l'avenir. Mais l'aspect le plus décisif du triptyque SoLoMo est sans doute ce qui a trait à la (géo)localisation. Tout comme avec Wikitude, le citoyen lambda est libre de recommander chaleureusement un restaurant ou de poster un commentaire assassin sur son expérience en tant que client. La e-réputation devient donc un capital précieux qu'il faut protéger, d'autant qu'il est bien difficile d'effacer de vilaines traces dans l'espace numérique.
Cela dit, cette problématique inhérente à la géolocalisation ne touche pas que les commerces. Les personnes sont aussi affectées. Et cela est grave quand on sait que la NSA parvient à accéder aux données contenues dans les téléphones portables, même quand ceux-ci sont déconnectés... De fait, rien n'empêche réellement les autorités américaines de vous suivre à la trace pour diverses raisons. Elles en sont capables, et elles en ont les moyens. Mais même sans aller jusque-là, la géolocalisation peut véritablement être préjudiciable si on s'en sert pour vous surveiller ou s'il y a des fuites. Un service comme Google Latitude, passé complètement inaperçu aux yeux des internautes, recueillait pourtant des données très précises sur vos déplacements quotidiens ; en se basant notamment sur l'activité de votre smartphone Android. Il n'y avait bien sûr aucune volonté de nuire de la part de Google, mais si on couple une telle application avec les principes du Patriot Act, cela nous donne un cocktail explosif pour notre vie privée car il devient évident que nous ne sommes plus les seuls à pouvoir consulter nos informations personnelles.
Dernier point, et non des moindres, mais qui cette fois ne concerne que les entreprises : le BYOD ( « Bring Your Own Device »). L'idée derrière le BYOD, c'est de permettre à des employés de venir au travail avec leurs propres terminaux (notamment smartphones et tablettes) afin de les utiliser comme outils professionnels. D'un côté, c'est positif, puisque les employés sont plus productifs avec leurs propres équipements, en plus du fait que cela ne nécessite aucun investissement. D'un autre côté, le BYOD représente une véritable passoire pour les DSI car les employés ont tendance à laisser échapper des informations qui sont parfois confidentielles, voire très sensibles. Cela paraît idiot, mais tout le monde ne se rend pas forcément compte que le simple fait de mettre des informations dans Dropbox ou Evernote, sans l'accord de la DSI, constitue un trou béant dans la stratégie sécuritaire qui a probablement été mise en place en amont.
e-Réputation & Web x.0
Maintenant que nous avons une idée concrète de ce qu'est en train de devenir notre e-réputation avec l'arrivée du « Web 3.0 », projetons-nous encore un peu plus dans l'avenir, et imaginons ce qui nous attend. On a vu que la société convergeait déjà vers une sorte de « Big Brother », c'est un fait. Or cela risque bien de s'accentuer, jusqu'à l'inacceptable !
Prenons par exemple ici le cas d'une série télévisée américaine, particulièrement intéressante pour illustrer notre propos : Person of Interest. Dans cette série, les protagonistes utilisent une « machine » omnisciente conçue par l'un d'entre eux – un hacker brillant – pour le compte du gouvernement. À l'origine, cet outil d'espionnage de masse devait servir pour prévenir les actes de terrorisme. Mais en réalité, la machine voit tout ce qui se passe dans l'espace social, 24h/24, grâce à une compilation en temps réel d'un volume important de données hétérogènes. Voilà déjà une limite évidente d'un Big Data non maîtrisé...
De nos jours, les données sont précieuses, surtout quand elles sont à caractère personnel. Rappelons qu'en France, la CNIL est là pour éviter toute dérive éventuelle. Mais le dispositif est-il suffisant ? Dans un avenir plus ou moins proche, il n'est pas à exclure que chaque individu soit autant – si ce n'est plus – connecté que Chris Dancy (« the most connected man »). Alors imaginons un seul instant que nous disposions tous d'une adresse IPv6 en guise d'identifiant unique ou d'une puce RFID sous-cutanée à la place de notre carte d'identité. Comment gérer les données personnelles dans un monde où la connectivité est partout, c'est-à-dire dans un monde où tout est traçable et piratable ? Si l'on reprend un vieil adage des spécialistes en sécurité informatique : « Un système sûr à 100 % est inutilisable. » En effet, pour qu'un ordinateur soit sûr à 100 %, le principe est de tout débrancher, de démonter les différents composants, et de répartir géographiquement ces pièces dans des lieux difficilement localisables. Sauf que dans le cas présent, l'ordinateur ne fonctionne plus. Mais si les ordinateurs font demain partie de nos vies biologiques, nous ne serons pas en mesure de nous débrancher. Le sort de la société sera donc entre les mains des machines, ce qui n'est pas sans rappeler une nouvelle fois le synopsis de la trilogie Matrix.
Conclusion
La e-réputation est assurément l'une des grandes questions de société d'aujourd'hui et de demain. Compte tenu du rythme effréné auquel progresse la technologie connectée, et donc de l'importance croissante que prend le virtuel, il est impératif de ne plus ignorer les enjeux sous-jacents à la gestion de son image numérique. Bien sûr, tout le monde n'a pas la fibre technophile, et il y aura de la résistance au changement. Malheureusement pour les technophobes, la révolution est déjà en marche.
Alors que la e-réputation était un jeu d'enfants à l'ère du « Web 1.0 », elle est devenue problématique avec le « Web 2.0 », puis elle semble en grand danger avec l'arrivée du « Web 3.0 ». Autant dire que nous avançons vers un avenir incertain car plus on incrémente le chiffre derrière le Web, plus notre e-réputation est en péril. Espérons alors que la technologie sera finalement plus clémente que ce qu'on peut voir dans certains scénarios de films post-apocalyptiques. Mais quitte à se lancer dans les conjectures, autant regarder cette vidéo qui nous livre une anticipation de ce qui va probablement nous arriver jusqu'en 2050 :
Bibliographie
- Anderson C., La longue traîne - La nouvelle économie est là !, Pearson, 2007
- Andrieu O., Réussir son référencement Web, Eyrolles, 2012
- Brahimi F., Schawbel D., Moi 2.0, Leduc.s, 2011
- Carr N., Internet rend-il bête ?, Robert Laffont, 2011
- Cousin C., Tout sur le Web 2.0 et 3.0, Dunod, 2010
- Scheid F., Vaillant R., de Montaigu G., Le marketing digital, Eyrolles, 2012
- Simone R., Pris dans la Toile - L'esprit aux temps du Web, Gallimard, 2012
Webographie
- Le Web 3.0 : état des lieux et perspectives d'avenir
- Le Web 3.0 est enfin là ! Mais c’est quoi ?
- Internet des objets: quelle place pour l’humain face à l’inflation de données?
- "Cybersécurité" WEB 3.0 et les nouveaux défis du Net : eRéputation
- L’Internet mobile une nouvelle menace pour l’e-réputation
- Séquence 0.1 Web2.0, Web 3.0
- WEB 3.0: s’adapter ou mourir ! Voici 5 tendances à surfer pour rester dans la course
- Le Knowledge Graph : outil d’e-réputation
- Internet de demain : les questions juridiques à résoudre
- L’avenir de l’internet est aux contenus, pas au SoLoMo
- La confidentialité compromise : une caractéristique saillante du web 3.0
- L’internet des objets en infographie
- Le web sémantique, futures approches et visions du web pensant
- Le Web 3.0 au service de l'entreprise
- E-réputation & Réalité augmentée
- Quelle place pour la langue et la culture française dans le web 3.0 ?
- Combien vaut votre e-réputation?
- La Cnil met les RFID et les fichiers de mauvais payeurs sur sa liste noire
- Objet 3.0, Objets intelligents ou Smart objects, vocabulaire étrange du Web 3.0
- Quel contrat social pour Facebook?
- Big data : comment l'intégrer à votre stratégie ?
- Relations professionnelles et web 3.0, la naissance d’un nouvel écosystème ?
- Un nouveau protocole pour l’Internet des objets
- Web 3.0 le futur en marche
- La réalité augmentée progresse encore grâce au MIT
- "Web Symbiotique ou Web 5.0"
- La réalité augmentée, le nouvel eldorado
- Vers un monde de réalité mixte grâce à la réalité augmentée
- La Lettonie, un havre pour l'informatique russe
- Google Glass, ou le monde en réalité augmentée
- L’internet des objets va disparaitre !
- Les nouveaux usages du Cloud Computing
- La réalité augmentée : l’avenir du marketing ?
- L'avenir sans nuage du Cloud Computing
- Créer de nouvelles opportunités avec le Cloud
- Intermarché imagine le shopping du futur avec les Connected Glasses
- L’expression "Internet des objets" est-elle appropriée ?
- Dossier : le cloud pour les nuls
- Inriality - La réalité augmentée en 90 secondes
- Le Cloud privé OpenSource : les clés pour en faire un véritable outil d’optimisation des performances
- 5 nouvelles tendances du Cloud Computing
- Qu’est-ce que la réalité augmentée et est-ce utile?
- C’est quoi l’Internet des Objets ? Quels risques pour la sécurité ?
- Chiffrement : la clé d’un cloud computing sécurisé ?
- Les enjeux juridiques du « Cloud Computing »
- Peut-on faire confiance au cloud computing ?
- "Les systèmes embarqués deviennent de plus en plus communiquants"
- En matière d'internet, on n'a encore rien vu
- Big Data : l’exploitation des données au cœur des préoccupations des DSI
- L’internet des objets et la connaissance de soi
- le cloud computing : une affaire de confiance
- Le cloud computing a besoin d’une régulation. Maintenant !
- Internet : quel sera l’avenir du web selon Cisco ?
- Internet des Objets, vers un nouveau monde 3.0.
- Le boom des objets connectés à Internet : quand votre boîte aux lettres vous enverra un SMS
- Le Cloud Computing à l’insu des DSI : les salariés français à l’origine de 1,7 million d'euros de dépenses par entreprise
- Faut-il confier nos vies à des puces ?
- Samsung travaille sur des lentilles intelligentes
- Vidéo Pierre Col – Antidot : « Web sémantique : une certaine confusion a été alimentée »
- Réconcilier Cloud Computing et ... sécurité !
- Le Cloud : « à l’insu de mon plein gré » ?
- Réalité augmentée, réalité mixte, vers un web symbiotique ?
- Internet des objets : Nice inaugure son boulevard connecté
- Quatre bonnes raisons de renoncer (si l’on peut) au cloud computing
- Le Cloud Computing transforme l’usage d’Internet
- «Sight» imagine le futur de la réalité augmentée
- Alzheimer: la géolocalisation pour sauver des malades
- L’internet des objets existe avec l’internet des gens
- Google Glass: un buzz et des questions
- Cloud computing : les 7 étapes clés pour garantir la confidentialité des données
- La sécurité des objets connectés
- Internet des objets : des appareils piratables, mais pour la bonne cause !
- Internet, prospective 2030 : l’Internet des objets pour sauver l’Europe ?
- Cloud : Amazon et IBM bataillent pour un contrat avec la CIA
- Le « cloud » à la française espère profiter du scandale Prism
- Aux US, la police n’a plus besoin de mandat pour récupérer vos données de géolocalisation mobile
- Scandale PRISM : le Cloud Computing descend de son nuage
- Protection des données et cloud
- Le scandale Prism pourrait coûter cher à l’industrie high-tech américaine
- Les Google Glass vont-elles causer un séisme dans le monde de la pub ?
- Excédé par la NSA, Wikipédia veut généraliser HTTPS et suggère TOR (MàJ)
- Le web 3.0, c'est pour quand ?
- La « police 3.0 » de Manuel Valls, formule magique et mystérieuse
- PayPal teste le paiement par reconnaissance faciale
- Cloud Computing : Amazon plus puissant qu’IBM, Microsoft et Google réunis
- Intercepter les données du dossier public de DropBox... facile
- Internet des objets : une formidable opportunité pour les entreprises
- Le sexe virtuel en sept étapes
- Le scandale PRISM coûtera jusqu'à 35 milliards de dollars aux acteurs américains du cloud
- L’avènement du cloud quantique
- Le Leti coordonne un projet de villes intelligentes mêlant Internet des Objets et cloud computing
- Les Objets Connectés : la nouvelle génération d'Internet ?
- Cloud Computing et protection des données : mariage heureux ou liaisons dangereuses ?
- Premier essai réussi dans l’interconnexion des cerveaux humains
- De l’internet des objets au web des objets
- Qui contrôle (vraiment) les objets connectés ?
- La NSA géolocalise des centaines de millions de téléphones portables
- États-Unis : les opérateurs ont fourni plus d'un million de données à la justice
- L' "Internet des objets": de nouveaux défis en matière de sécurité
- Le Sénat adopte le projet de loi sur la géolocalisation
- Internet des objets et « Transhumanisme », ou comment l’homme devient une machine
- Cloud Computing : Pour contrer au mieux les menaces informatiques.
- Le sur-mesure en guise de sécurisation des systèmes M2M
- Proofpoint révèle l’existence de cyberattaques perpétrées via l'Internet des objets
- La protection des données : Quel rôle pour le fournisseur Cloud ?
- Les objets connectés, prémices du Web 3.0 ?
- Sécurisation de l’internet des objets, des systèmes d’exploitation mobiles et du cloud : Grandes tendances et challenges pour les entreprises en 2014
- Internet des objets et données personnelles